Web scraping
Lecture 13
Duke University
STA 199 - Fall 2022
October 12, 2022
rvest
- The rvest package makes basic processing and manipulation of HTML data straight forward
- It’s designed to work with pipelines built with
|> - rvest.tidyverse.org

Ethics: “Can you?” vs “Should you?”
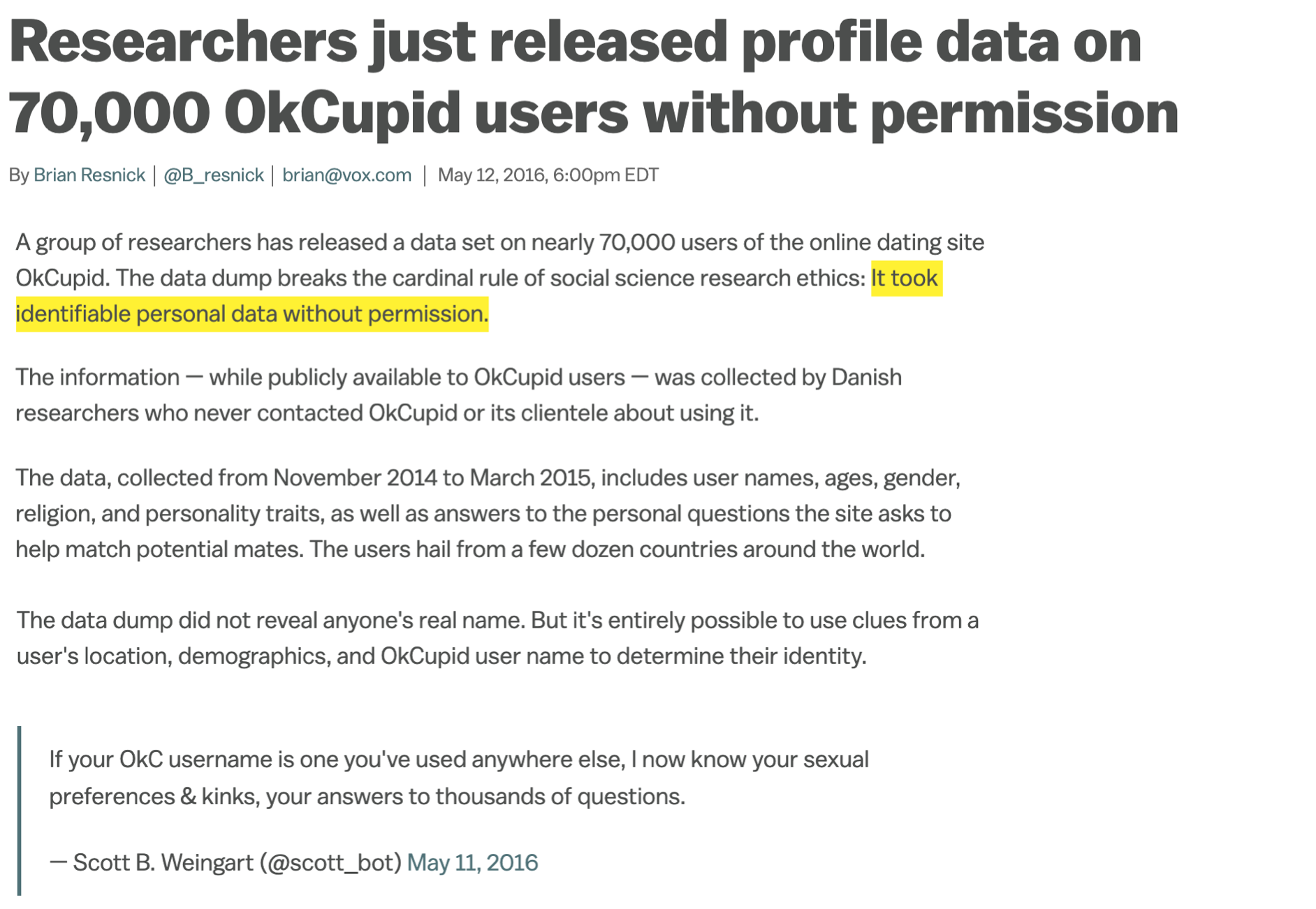
“Can you?” vs “Should you?”
Challenges: Unreliable formatting
Challenges: Data broken into many pages
Workflow: Screen scraping vs. APIs
Two different scenarios for web scraping:
Screen scraping: extract data from source code of website, with html parser (easy) or regular expression matching (less easy)
Web APIs (application programming interface): website offers a set of structured http requests that return JSON or XML files