F_to_C <- function(temp_F){
temp_C <- (temp_F - 32) * 5/9
return(temp_C)
}
F_to_C(75)[1] 23.88889#Warm Up
To convert temperatures in degrees Fahrenheit to Celsius, subtract 32 and multiply by .5556 (or 5/9). Write a function below to do this:
F_to_C <- function(temp_F){
temp_C <- (temp_F - 32) * 5/9
return(temp_C)
}
F_to_C(75)[1] 23.88889If needed, go to https://www.dukechronicle.com/section/opinion
Let’s start by loading the packages we will need:
chronicle <- read_csv("data/chronicle.csv")chronicle |>
count(author, sort = T)# A tibble: 69 × 2
author n
<chr> <int>
1 Anthony Salgado 3
2 Billy Cao 3
3 Community Editorial Board 3
4 Heidi Smith 3
5 Linda Cao 3
6 Luke A. Powery 3
7 Monday Monday 3
8 Sonia Green 3
9 Viktoria Wulff-Andersen 3
10 Abdel Shehata 2
# … with 59 more rowsHint: https://cran.r-project.org/web/packages/stringr/vignettes/stringr.html (Look at the Locale Sensitive section)
Hint: Think about creating a new variable
chronicle |>
mutate(
title = str_to_lower(title),
climate = if_else(str_detect(title, "climate"), "mentioned", "not mentioned")
) |>
count(climate) |>
mutate(prop = n / sum(n))# A tibble: 2 × 3
climate n prop
<chr> <int> <dbl>
1 mentioned 3 0.03
2 not mentioned 97 0.97chronicle |>
mutate(
title = str_to_lower(title),
abstract = str_to_lower(abstract),
climate = if_else(
str_detect(title, "climate") | str_detect(abstract, "climate"),
"mentioned" , "not mentioned")
) |>
count(climate) |>
mutate(prop = n / sum(n))#Amazon Candle
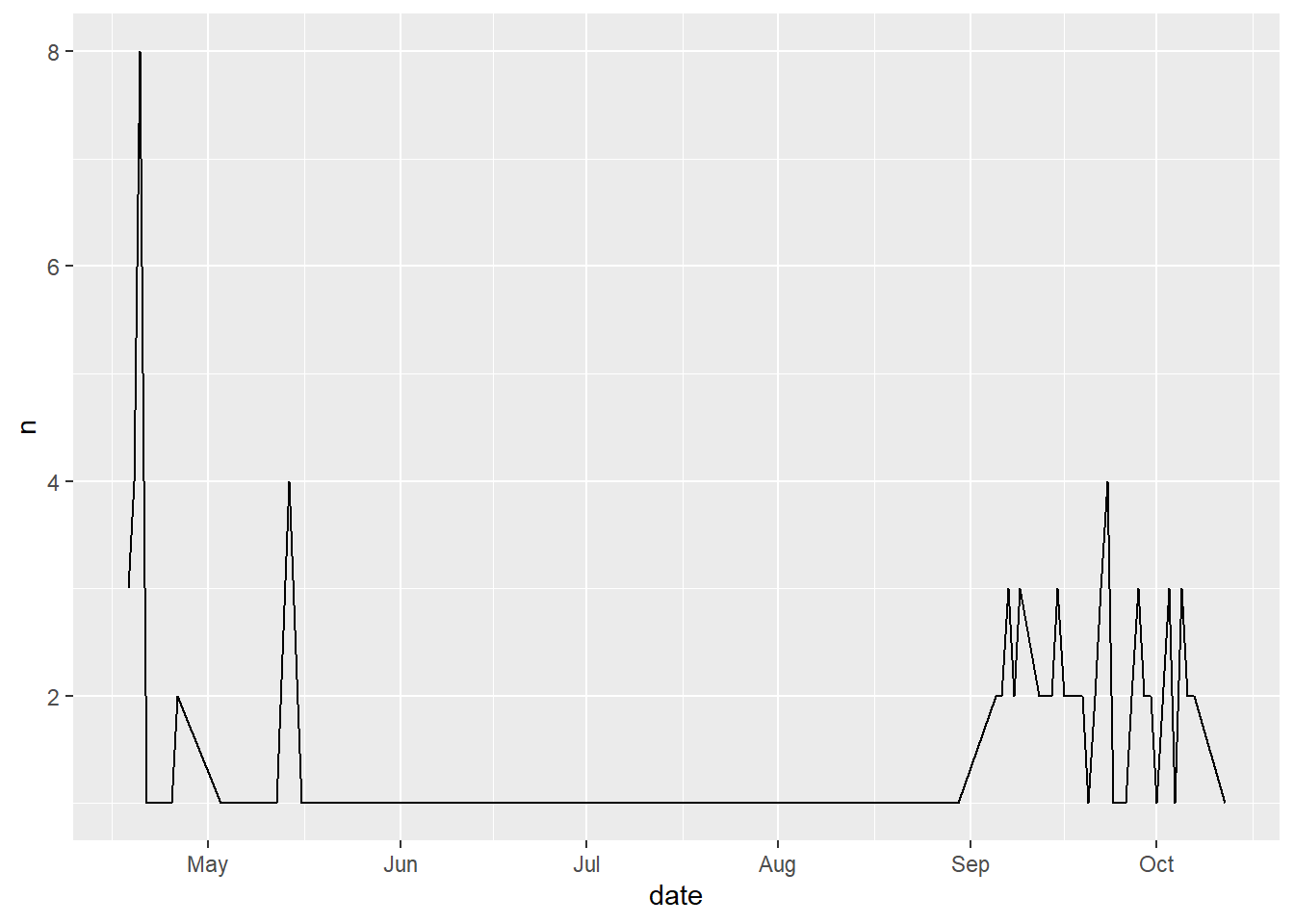
 A researcher is interested in the manufacturing process of this candle. Specifically, they are interested in if it’s potency has become less over time. In this exercise, our goal is to plot the number of reviews mentioning “no scent” or “no smell” per week. For the purpose of this exercise, we will only use the first 10 pages of reviews.
A researcher is interested in the manufacturing process of this candle. Specifically, they are interested in if it’s potency has become less over time. In this exercise, our goal is to plot the number of reviews mentioning “no scent” or “no smell” per week. For the purpose of this exercise, we will only use the first 10 pages of reviews.
Go to the link here
Think critically about how we would scrape the titles of the review, the review itself, and where/when the review was given from. Next, run the following code to do so below:
page <- read_html("https://www.amazon.com/Yankee-Candle-Large-Apple-Pumpkin/product-reviews/B008P8YTU6/ref=cm_cr_getr_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=1&sortBy=recent")
titles <- page |>
html_nodes("#cm_cr-review_list .celwidget .a-row:nth-child(2)") |>
html_text2()
reviews <- page |>
html_nodes(".a-spacing-small.review-data") |>
html_text2()
countries_dates <- page |>
html_nodes("#cm_cr-review_list .review-date") |>
html_text2()
#Build data set
amazon <- tibble(
title = titles,
review = reviews,
country_date = countries_dates
)##Write function
– Why do we need a function?
Add your response here.
scrape_review <- function(url){
Sys.sleep(2)
page <- read_html(url)
titles <- page |>
html_nodes("#cm_cr-review_list .celwidget .a-row:nth-child(2)") |>
html_text2()
reviews <- page |>
html_nodes(".a-spacing-small.review-data") |>
html_text2()
countries_dates <- page |>
html_nodes("#cm_cr-review_list .review-date") |>
html_text2()
tibble(
title = titles,
review = reviews,
country_date = countries_dates
)
}##Test your function
# page 1
scrape_review("https://www.amazon.com/Yankee-Candle-Large-Apple-Pumpkin/product-reviews/B008P8YTU6/ref=cm_cr_getr_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=1&sortBy=recent")# A tibble: 10 × 3
title review count…¹
<chr> <chr> <chr>
1 5.0 out of 5 stars SMELLS GREAT This pump… "Revie…
2 1.0 out of 5 stars Very little scent, not worth the price What is i… "Revie…
3 3.0 out of 5 stars Arrived with glass smashed I have or… "Revie…
4 5.0 out of 5 stars Amazing value I love ya… "Revie…
5 1.0 out of 5 stars Not stored properly; melted I ordered… "Revie…
6 1.0 out of 5 stars NO SMELL!! VERY DISSATISFIED!! Used it f… "Revie…
7 1.0 out of 5 stars BUYER BEWARE/ THIS IS NOT YANKEE CANDLE I bought … "Revie…
8 1.0 out of 5 stars zero scent this is n… "Revie…
9 2.0 out of 5 stars Disappointed I love th… "Revie…
10 2.0 out of 5 stars Arrived melted The candl… "Revie…
# … with abbreviated variable name ¹country_date# page 2
scrape_review("https://www.amazon.com/Yankee-Candle-Large-Apple-Pumpkin/product-reviews/B008P8YTU6/ref=cm_cr_getr_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=2&sortBy=recent")# A tibble: 10 × 3
title review count…¹
<chr> <chr> <chr>
1 5.0 out of 5 stars SMELLS GOOD! I don… "Revie…
2 1.0 out of 5 stars Cannot be used : melted when arrived Likel… "Revie…
3 1.0 out of 5 stars Not a Yankees Candle There… "Revie…
4 1.0 out of 5 stars No scent whatsoever I sup… "Revie…
5 5.0 out of 5 stars Wonderful candle Got t… "Revie…
6 1.0 out of 5 stars I really wanted to like it, but… It tu… "Revie…
7 4.0 out of 5 stars Smells good. Would… "Revie…
8 5.0 out of 5 stars Damaged Candl… "Revie…
9 1.0 out of 5 stars Wrong Scent Wood wick candle!! False adver… I don… "Revie…
10 5.0 out of 5 stars Good scent Smell… "Revie…
# … with abbreviated variable name ¹country_date# page 3
scrape_review("https://www.amazon.com/Yankee-Candle-Large-Apple-Pumpkin/product-reviews/B008P8YTU6/ref=cm_cr_getr_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=3&sortBy=recent")# A tibble: 10 × 3
title review count…¹
<chr> <chr> <chr>
1 4.0 out of 5 stars Average candle "This… Review…
2 5.0 out of 5 stars A Softer and Warmer scent than you might e… "The … Review…
3 2.0 out of 5 stars Barely has any scent "I'd … Review…
4 1.0 out of 5 stars No emana ningún olor "Esta… Review…
5 5.0 out of 5 stars Nice scent last long nice to give as a Chr… "Gift… Review…
6 4.0 out of 5 stars Smell wasn't strong "Scen… Review…
7 5.0 out of 5 stars Beautiful! "I've… Review…
8 1.0 out of 5 stars Came ruined "Melt… Review…
9 5.0 out of 5 stars This is the only one buy "Make… Review…
10 5.0 out of 5 stars Can't go wrong with a classic! "I lo… Review…
# … with abbreviated variable name ¹country_date– What changes across URLs?
Add your response here.
You can use the paste() and paste0() functions in R to concatenate elements of a vector into a single string. The paste0() function concatenates strings using no space as the default separator.
Use this information to create a list of urls for the first 10 pages of the amazon review.
yc_urls <- paste0("https://www.amazon.com/Yankee-Candle-Large-Apple-Pumpkin/product-reviews/B008P8YTU6/ref=cm_cr_getr_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=", 1:10, "&sortBy=recent" )We have a function. We have a lot of urls. How do we iterate?
Add your response here.
yc_reviews_all <- map_dfr(yc_urls , scrape_review)We have the data! Let’s clean it up. We need to get the date in working order and createad week variable. We also need to create a variable that detects if “no scent” or “no smell” is mentioned.
Below, document what each line of code is doing.
yc_reviews <- yc_reviews_all |>
mutate(
date = mdy(country_date),
week = week(date),
review = str_to_lower(review),
title = str_to_lower(title),
no_scent = case_when(
str_detect(review, "no scent") | str_detect(title, "no scent") ~ "mentioned",
str_detect(review, "no smell") | str_detect(title, "no smell") ~ "mentioned",
TRUE ~ "not mentioned"
)
)Using the code above, make a line graph by week for the number of reviews that contained “no scent” or “no smell”.
# add-code-hereAdd your response here.