Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
See https://scales.r-lib.org/reference/index.html for inspiration and help with scales.
In September 2019, YouGov survey asked 1,639 GB adults the following question:
In hindsight, do you think Britain was right/wrong to vote to leave EU?
Right to leave
Wrong to leave
Don’t know
The data from the survey is in data/brexit.csv.
In this application exercise we will explore how different axes can tell different stories of data.
Rows: 1639 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): opinion, region
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
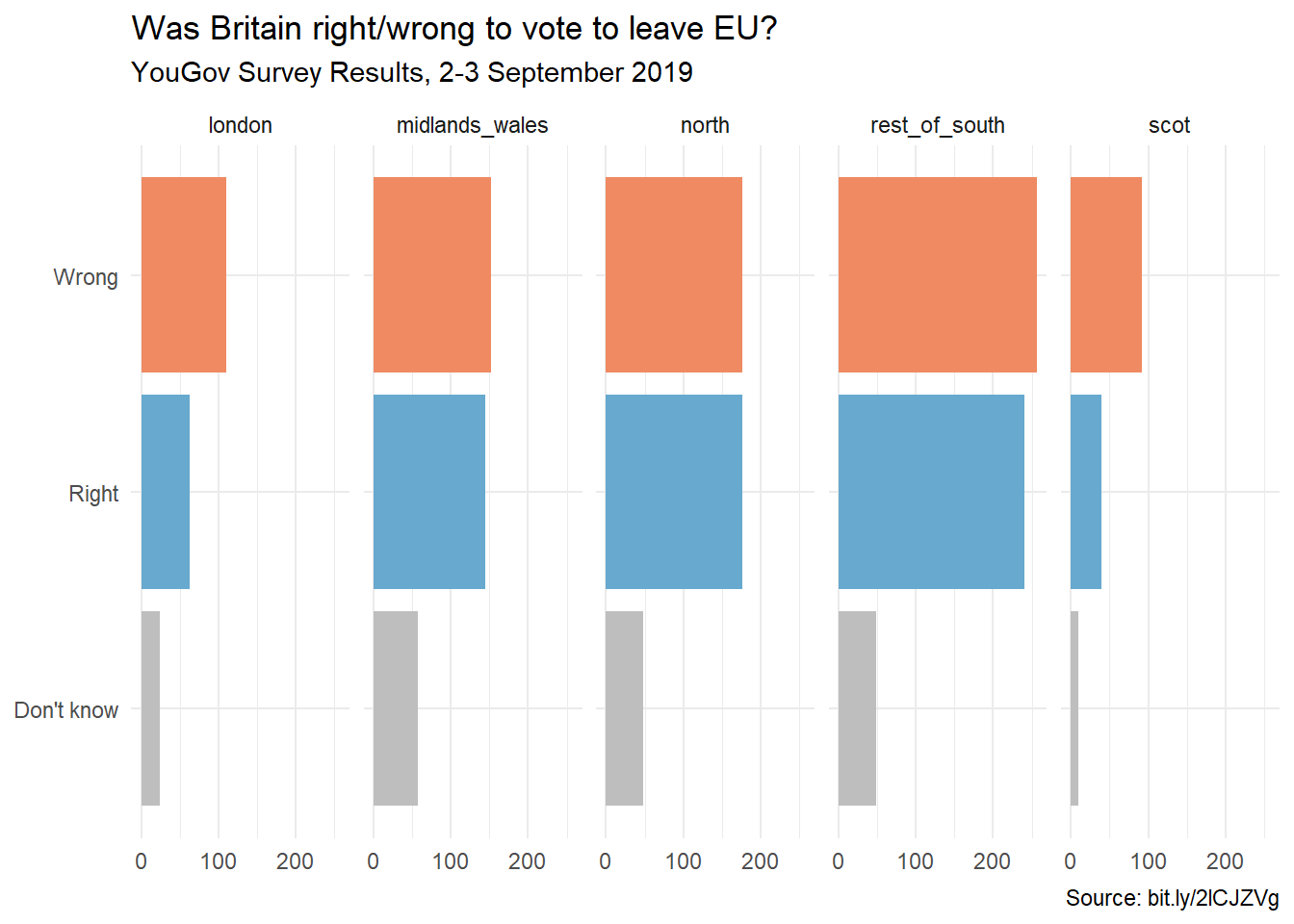
Create a segmented bar plot facet by region to explore counts of votes to the question Was Britain right/wrong to leave EU.
ggplot(brexit, aes(y =opinion, fill =opinion))+geom_bar()+facet_wrap(~region, nrow =1, labeller =label_wrap_gen(width =12))+guides(fill ="none")+labs( title ="Was Britain right/wrong to vote to leave EU?", subtitle ="YouGov Survey Results, 2-3 September 2019", caption ="Source: bit.ly/2lCJZVg", x =NULL, y =NULL)+scale_fill_manual(values =c("Wrong"="#ef8a62","Right"="#67a9cf","Don't know"="gray"))+theme_minimal()
Comment on the plot. What do you notice? What story is it telling?
This plot is showing the difference in how each region voted on the question above. Because of the scale of the graph, it appears that London has minimal differences in how they voted between yes and no, while other differences are more extreme.
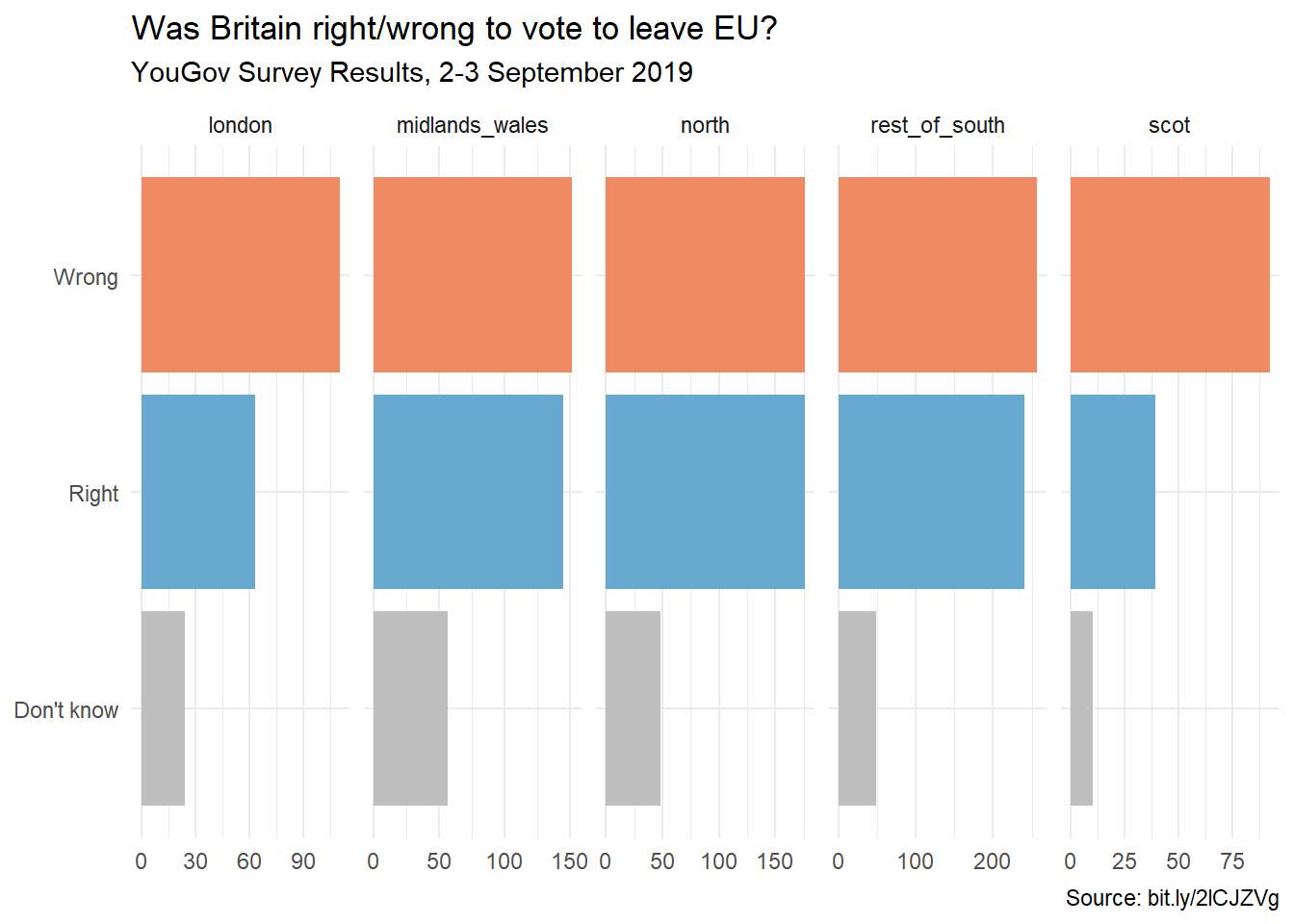
Next, use scales = "free_x" as an argument to the facet_wrap() function. How does the visualisation change? How is the story this visualisation telling different than the story the original plot tells?
ggplot(brexit, aes(y =opinion, fill =opinion))+geom_bar()+facet_wrap(~region, nrow =1, labeller =label_wrap_gen(width =12), scales ="free_x"# add scales = "free_x" here)+guides(fill ="none")+labs( title ="Was Britain right/wrong to vote to leave EU?", subtitle ="YouGov Survey Results, 2-3 September 2019", caption ="Source: bit.ly/2lCJZVg", x =NULL, y =NULL)+scale_fill_manual(values =c("Wrong"="#ef8a62","Right"="#67a9cf","Don't know"="gray"))+theme_minimal()
What changed? Is this plot more or less appropriate?
The x-axis is different. It is easier to see the within region differences.
Exercise 2 - Comparing proportions across facets
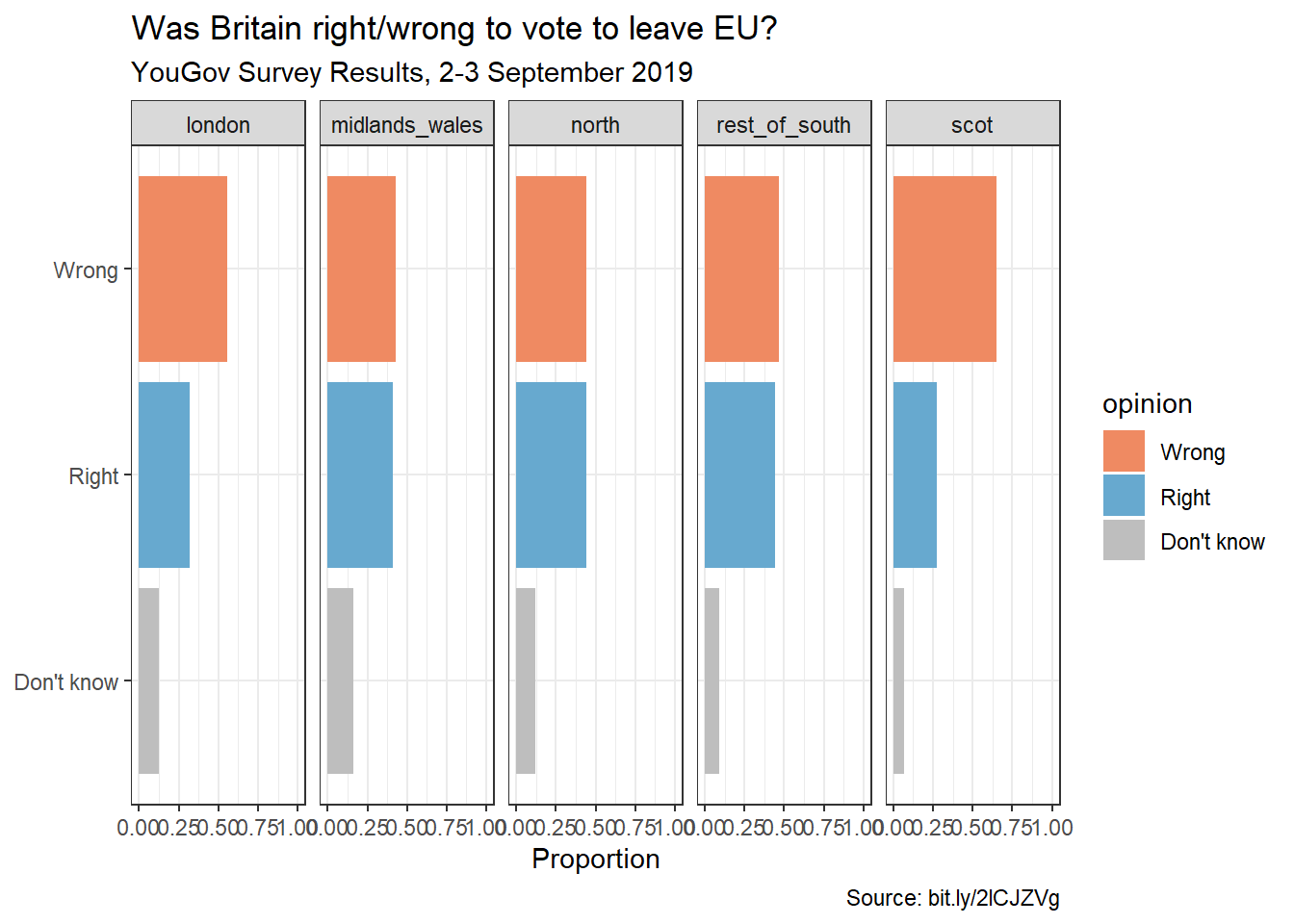
First, calculate the proportion of wrong, right, and don’t know answers in each category and then plot these proportions (rather than the counts) and then improve axis labeling. How is the story this visualization telling different than the story the original plot tells? Hint: You’ll need the scales package to improve axis labeling.
#Take notes on code using comments brexit|>group_by(region, opinion)|>summarize(n =n())|>mutate(freq =n/sum(n))|>ggplot()+geom_bar(aes(y =opinion, x =freq, fill =opinion), stat ="identity")+facet_wrap(~region, nrow =1)+scale_x_continuous(limits =c(0,1))+theme_bw()+labs( title ="Was Britain right/wrong to vote to leave EU?", subtitle ="YouGov Survey Results, 2-3 September 2019", caption ="Source: bit.ly/2lCJZVg", y =NULL, x ="Proportion")+scale_fill_manual(values =c("Wrong"="#ef8a62","Right"="#67a9cf","Don't know"="gray"))
`summarise()` has grouped output by 'region'. You can override using the
`.groups` argument.
Optional
Exercise 3 - adding visual uncertanity
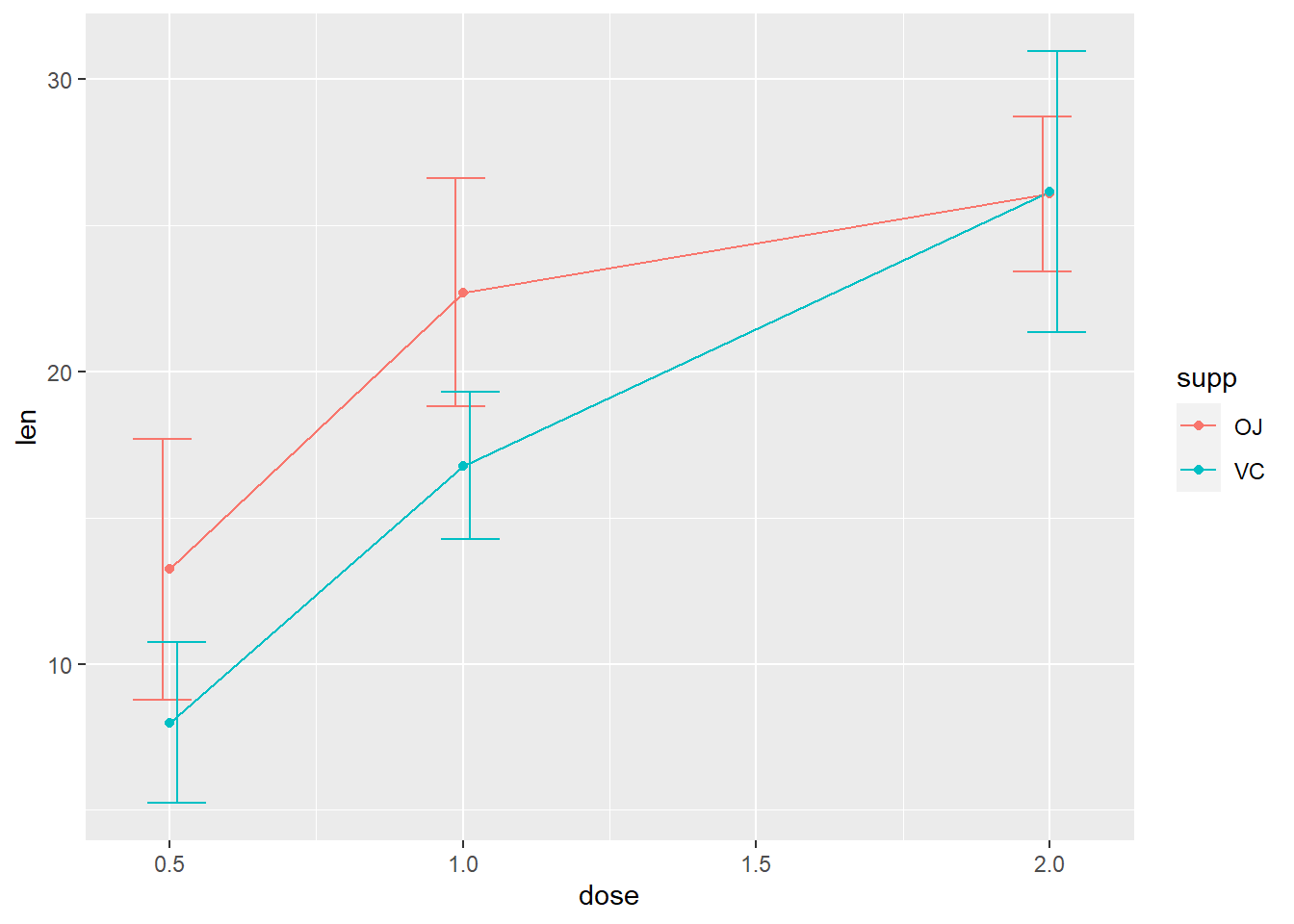
The Effect of Vitamin C on Tooth Growth in Guinea Pigs: The response is the length of odontoblasts (cells responsible for tooth growth) in 60 guinea pigs. Each animal received one of three dose levels of vitamin C (0.5, 1, and 2 mg/day) by one of two delivery methods, orange juice or ascorbic acid (a form of vitamin C and coded as VC).
Demo Make a line plot to show the length of tooth growth by the dose of vitamin C they received. Include error bars that range 1 SD away from the estimate in both directions.
Rows: 6 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): supp
dbl (3): dose, len, sd
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.